The purpose of this article is to suggest how to include Old English and Middle English scripts in web pages and to provide a comprehensive glyph-to-code reference table for Old English and Middle English letters. The results achieved by the method described in this article are assumed to be displayed correctly on Microsoft Windows 98/ME/NT/2000/XP operating systems in most Unicode compliant web browsers. Users of other operating systems are advised to consult the information available on the “Display Problems?” web page of the Unicode Consortium.
Including Old English and Middle English scripts in a web page may not be an easy task to do, but the development of the Unicode character set together with the UTF-8 character encoding may significantly help anyone faced with this task. The linguists or literary historians who will make use of the Unicode character sets when writing their web articles can then be fairly sure that the results of their work will be displayed correctly for the majority of the readers of their web pages/articles. The following text, an Old English version of Our Father [Hladký 2003, p. 107], illustrates the results of using Unicode to include an Old English script in this article. The Old English text is followed by a check image containing the same text. Users of Unicode compliant browsers and above mentioned operating systems should see the two texts as identical:
Þū ūre fæder, þe eart on heofonum, sȳ þīn nama ʒehālʒod.
Cume ðīn rīce.
Sȳ ðīn wylla on eorðan swāswā on heofonum.
Syle ūs tōdæʒ ūrne dæʒhwāmlican hlāf.
And forʒyf ūs ūre ʒyltas swāswā wē forʒyfað ðāmþe wið ūs āʒyltað.
And ne lǣd ðū nā ūs on costnunʒe, ac ālȳs ūs fram ȳfele.

Check Image
The principle lying behind the correct rendering of Old English (and Middle English) scripts on the web is relatively simple. The correct rendering is possible due to the fact that the Old-English-specific letters of the prayer were encoded into their Unicode values so that they could be displayed in a Unicode font in which any character is represented as a special 16-bit long Unicode value. Using this 16-bit encoding “means that code values are available for more than 65,000 characters. While this number is sufficient for coding the characters used in the major languages of the world, the Unicode Standard and ISO/IEC 10646 provide the UTF-16 extension mechanism (called surrogates in the Unicode Standard), which allows for the encoding of as many as 1 million additional characters without any use of escape codes” [see Unicode 3.0, Chapter 1 - Introduction].
Given such ranges of possible characters and character sets one would expect that Old English and Middle English letters are readily available in any Unicode compliant font. However, the current Unicode specification does not list a character set or subset [see Code charts] designed specifically for Old English and Middle English. Fortunately it is still possible to assemble Old English and Middle English scripts using a variety of characters belonging to other existing Unicode character sets namely to Basic Latin, Latin-1 Supplement, Latin Extended-A, Latin Extended-B, IPA Extensions, and Combining Diacritical Marks, all of them being available in a single font installed on a computer.
Thus, one way of writing the last word of the above Old English prayer, i.e. the word ȳfele, is to use the Unicode values, or in fact their UTF-8 character entity representations, for the non-ASCII characters of the word. The letters in the component fele of the word are of course directly available on English keyboards so there is no need to write them using their Unicode values. On the other hand, the letter ȳ is accesssible only through its Unicode value. The whole ASCII-based representation of the word ȳfele would then be
ȳfele
where the part ȳ is the Unicode-based character entity for the letter ȳ. This character entity uses a hexadecimal Unicode number, but it is also possible to use decimal numbers (a way used hereinafter):
ȳfele
We could now take a look at how the code would be displayed in a Unicode compliant browser, but before doing it, we must somehow specify in the HTML code of the web page that the browser should use a Unicode font to display the word. On Windows 98 and higher there is a Unicode font called Lucida Sans Unicode we will use and this is how it should be done in the HTML code of the web page (line breaks have no meaning here):
<SPAN class="font-family: Lucida Sans Unicode">
ȳfele
</SPAN>
For articles to be published in Philologica.net it is sufficient to enclose it in the following way:
<SPAN class="pme">ȳfele</SPAN>
Using the decimal Unicode value 563 (or the hexadecimal Unicode value 0233) for the letter ȳ will not, however, produce the expected result.
The number will display ȳ (in picture: 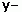 ), which means that the letter ȳ is not displayed correctly in the Lucida Sans Unicode font. (The small framed picture shows what the Unicode value actually displayed at the time of writing this article.)
), which means that the letter ȳ is not displayed correctly in the Lucida Sans Unicode font. (The small framed picture shows what the Unicode value actually displayed at the time of writing this article.)
Fortunately, there is a workaround for such cases. The letter ȳ can also be written as a combination of an ASCII character y and a combining macron, which is a Unicode name for the sign appearing above the letter ȳ. So, knowing the decimal Unicode value for the combining macron (772), we can write
ȳfele
to get the word ȳfele displayed correctly.
Nonetheless, even the Unicode standard is in continual development and its current version does not quite satisfactorily address the need for some other Old English characters, especially for letters representing Old English long diphthongs, in which “the same sound was heard [as in the corresponding short diphthongs] but the whole glide (and not simply the first element of it) was given greater length” [Quirk - Wrenn 1994, p. 14]. The problem can be illustrated by the following Old English class II. strong verbs:
lēosan [Blake 1996, p. 67]
lēōfian [Hladký 2003, p. 136]
(for)le̅o̅san [Quirk - Wrenn 1994, p. 48]
All of the three examples show that there are several ways of how to represent Old English long diphthongs. While it seems that Unicode makes it possible to render all of them, other variants of Old English long diphthongs are difficult to form using the current Unicode character sets. This is especially true of the long diphthongs beginning in ı, for example those that arise from diphthongization before velarized consonants (‘breaking’):
lı̅o̅ht
The difficulty lies in the part of the character used to represent the length of the i-diphthong. In the case of the words (for)le̅o̅san and lı̅o̅ht it is not the combining macron as in all the other cases before, but a combining overline that is used here to represent the length of the diphthong. Unlike the combining macron, the combining overline corresponds best to the Quirk-Wrenn explanation, but unfortunately it is too wide for the diphthongs beginning in ı.
This is a point that should be addressed in future versions of the Unicode standard possibly by introducing a set of paired characters of the nj type found in the Latin Extended-B set, but with one longer combining macron above the whole pair.
For the sake of simplicity and future compatibility, I suggest that the authors follow the way shown in Hladký’s example, i.e. to use the combining macron for each component of the diphthong:
līōht
The following reference tables present the most common types of Old English and Middle English letters (called glyphs in the tables) used in transcriptions of Old English and Middle English texts. The glyphs are given together with their HTML character entity codes based on their decimal Unicode values, followed by the Unicode name, and examples of usage. Similar tables are available for IPA transcriptions from Professor John Wells on his International Phonetic Alphabet in Unicode web page.
Unicode Reference Table for Old English and Middle English
| Glyph |
its HTML Code |
its UNICODE Name |
| |
|
Example |
its HTML Code |
| ā |
ā |
latin small letter a with macron |
| |
|
hlāf |
hlāf |
| Ā |
Ā |
latin capital letter a with macron |
| |
|
HLĀF |
HLĀF |
| ē |
ē |
latin small letter e macron |
| |
|
hēr |
hēr |
| Ē |
Ē |
latin capital letter e macron |
| |
|
HĒR |
HĒR |
| ō |
ō |
latin small letter o with macron |
| |
|
fōt |
fōt |
| Ō |
Ō |
latin capital letter o with macron |
| |
|
FŌT |
FŌT |
| ǒ |
ǒ |
latin small letter o with caron |
| |
|
drǒghte |
drǒghte |
| Ǒ |
Ǒ |
latin capital letter o with caron |
| |
|
DRǑGHTE |
DRǑGHTE |
| ū |
ū |
latin small letter u with macron |
| |
|
nū |
nū |
| Ū |
Ū |
latin capital letter u with macron |
| |
|
NŪ |
NŪ |
| ī |
ī |
latin small letter i with macron |
| |
|
bītan |
bītan |
| Ī |
Ī |
latin capital letter i with macron |
| |
|
BĪTAN |
BĪTAN |
| æ |
æ |
latin small letter ae |
| |
|
fæt |
fæt |
| Æ |
Æ |
latin capital letter ae |
| |
|
ÆLFRIC |
ÆLFRIC |
| ǣ |
ǣ |
latin small letter ae with macron |
| |
|
slǣpan |
slǣpan |
| Ǣ |
Ǣ |
latin capital letter ae with macron |
| |
|
SLǢPAN |
SLǢPAN |
| þ |
þ |
latin small letter thorn |
| |
|
þridda |
þridda |
| Þ |
Þ |
latin capital letter thorn |
| |
|
ÞRIDDA |
ÞRIDDA |
| ð |
ð |
latin small letter eth |
| |
|
ðonne |
ðonne |
| Ð |
Ð |
latin capital letter eth |
| |
|
ÐONNE |
ÐONNE |
| ġ |
ġ |
latin small letter g with dot above |
| |
|
ġiefan |
ġiefan |
| Ġ |
Ġ |
latin capital letter g with dot above |
| |
|
Ġive |
Ġive |
| ǧ |
ǧ |
latin small letter g with caron |
| |
|
ǧyngle |
ǧyngle |
| Ǧ |
Ǧ |
latin capital letter g with caron |
| |
|
ǦYNGLE |
ǦYNGLE |
| ʒ |
ʒ |
latin small letter ezh |
| |
|
ʒyltas |
ʒyltas |
| Ʒ |
Ʒ |
latin capital letter ezh |
| |
|
ƷYLTAS |
ƷYLTAS |
| ċ |
ċ |
latin small letter c with dot above |
| |
|
ċild |
ċild |
| Ċ |
Ċ |
latin capital letter c with dot above |
| |
|
ĊILD |
ĊILD |
Combining Diacritical Marks
| Glyph |
its HTML Code |
its UNICODE Name |
| |
|
Example |
its HTML Code |
| ̄ |
̄ |
combining macron |
| |
|
ȳfele |
ȳfele |
| ̅ |
̅ |
combining overline |
| |
|
be̅o̅dan |
be̅o̅dan |
| ̇ |
̇ |
combining dot above |
| |
|
leġer |
leġer |
| ̣ |
̣ |
combining dot below |
| |
|
bẹẹn |
bẹẹn |
| ̨ |
̨ |
combining ogonek |
| |
|
mǫǫst |
mǫǫst |
| ́ |
́ |
combining acute accent |
| |
|
abóve |
abóve |
| ̌ |
̌ |
combining caron |
| |
|
drǒghte |
drǒghte |
Bibliography
“ASCII” [online], Webopedia, Jupitermedia Corporation, 5 Agust 2002 [cited 2004-1-3]. Available from World-Wide-Web: <http://www.webopedia.com/TERM/A/ASCII.html>.
Blake, N. F.: A history of the English Language, New York: New York University Press, 1996, ISBN 0-8147-1313-0.
“Code Charts” [online], unicode.org, The Unicode Consortium, 21 October 2003 [cited 2004-1-3]. Available from World-Wide-Web: <http://www.unicode.org/charts/>.
Cruz, F. da: “Representing Middle English Manuscripts on the Web with UTF-8” [online], Academic Information Systems (Columbia University), Aug 2002 - Jun 2003 [cited 2004-1-1]. Available from World-Wide-Web: <http://www.columbia.edu/kermit/st-erkenwald.html>.
”Display Problems?” [online], unicode.org, The Unicode Consortium, 16 October 2003 [cited 2003-12-29]. Available from World-Wide-Web: <http://www.unicode.org/help/display_problems.html>.
Hladký, J.: A Guide to Pre-Modern English, 1st Edition, Brno: Masaryk University, 2003, ISBN 80-210-3219-7.
Freeborn, D.: From Old English to Standard English, 2nd Edition, Ottawa: University of Ottawa Press, 1998, ISBN 0-7766-0469-4.
Pullum, G. K. & W. A. Ladusaw: Phonetic Symbol Guide, 2nd Edition, Chicago: The University of Chicago Press, 1996, ISBN 0-226-68536-5.
Quirk, R. & C. L. Wrenn: An Old English Grammar, DeKalb: Northern Illinois University Press, 1994, ISBN 0-87580-560-4.
“Unicode 3.0, Chapter 1 - Introduction” [online], unicode.org, The Unicode Consortium, 24 April 2003 [cited 2004-1-3]. Available from World-Wide-Web: <http://www.unicode.org/book/uc20ch1.html>.
Vachek, J. & J. Firbas: Historický vývoj angličtiny [Historical Development of English], 8th Edition, Brno: Masaryk University, 1994, ISBN 80-210-0487-8.
Wells, J.: “The International Phonetic Alphabet in Unicode” [online], 2 September 2003 [cited 2003-29-12]. Available from World-Wide-Web: <http://www.phon.ucl.ac.uk/home/wells/ipa-unicode.htm>.
“What is Unicode?” [online], unicode.org, The Unicode Consortium, 18 April 2003 [cited 2003-12-29]. Available from World-Wide-Web: <http://www.unicode.org/standard/WhatIsUnicode.html>.